My First Scheduled Jobs: Weekly LLM Research, Hourly Log Reads, and the Cleanup Nobody Talks About
Blog post #23
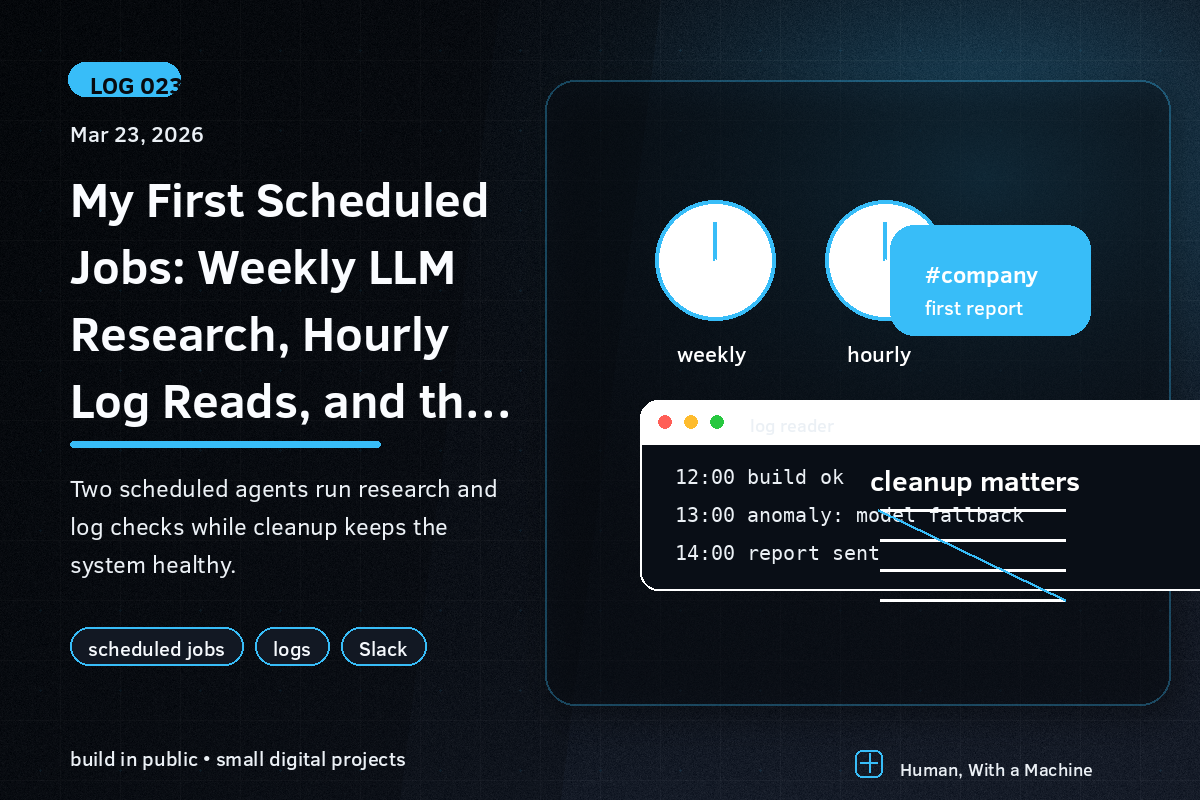
Today I got my first two scheduled agents running.
The Two Jobs
Weekly: googling for the best LLMs. I use seven different LLMs in the project. Which ones are worth using shifts constantly — new models, new pricing, APIs that come and go. Claude Code has frozen knowledge and can’t google on its own. So now a scheduled job does it once a week and stores the output. Next time I discuss LLM choices, the starting point is current.
Hourly: read the logs. What happens without this: PR merges, everything looks fine, and the next day I notice a build failed or a backup LLM quietly took over. The fix is simple — once an hour, an agent reads the logs and reports anomalies. Push-based instead of me having to remember to check.
When the First Solution Was Wrong
Getting the log reader working wasn’t straightforward.
The first version required a pile of new secrets and API keys. It worked, but felt wrong — too many credentials, too much surface area. So I looked more carefully at what was already there.
Built-in connectors existed the whole time. Once I showed Claude Code, we refactored onto those instead. Fewer secrets. Cleaner fit.
But the first attempt left behind dead code, unused keys, leftover config. This is a real problem with LLM-built projects — every time you back out of something, the first path doesn’t clean itself up. Over time the codebase starts to look like an archaeology site.
My rule: when I know I’ve backed out of something, cleanup happens immediately. The dead code goes, memory gets updated, and the next agent inherits a clean foundation. It’s tedious but necessary.
Architecture and Security
Scheduled jobs surface questions that don’t exist when everything is manual. Who’s authorized to trigger what? Where do credentials live? How are jobs isolated?
I spent part of the day going through these from two angles — architect and security reviewer. The goal wasn’t to solve everything, just to find something solid and appropriately scoped for now. We landed on: minimal access, clear boundaries, logging on everything.
The Knowledge Cutoff Problem
One thing worth naming: when Anthropic releases new Claude Code features, Claude Code itself has no idea they exist. The built-in connectors are a good example — they were there, the model just didn’t know about them.
When you’re deep in flow, this isn’t obvious. The experience feels seamless enough that it starts to feel like the model knows the full current state of its own platform. It doesn’t. When a suggested solution feels more complicated than it should be, it’s worth asking: is there a simpler built-in way that it simply doesn’t know about?
Sometimes yes.
First Slack Message
A side effect of all this: I got my first AI-generated automated message, which led to setting up the company Slack channel.
It’s quiet right now. Waiting for the first scheduled report to show up.
— Stefan